Stable Audio 2.0: Exploring the New Audio-to-Audio Feature
- Ezra Sandzer-Bell
- Apr 3, 2024
- 11 min read
Updated: Feb 25
Stability is one of the top AI companies in the world. Most people became aware of them through their open source image generation model, Stable Diffusion, but the company has invested a lot of time and capital into AI music generation as well.
On April 3rd 2024, the team released Stable Audio 2.0 with a variety of new and impressive features. The most noteworthy update is an audio-to-audio capability that was currently only available through its competitor, MusicGen by Meta.
The company's first efforts at music came through free and open source models developed by a branch called Harmonai. By September 2023, Stability announced the release of Stable Audio, their first for-profit music generation model. Within hours of launching, the product received glowing reviews from Billboard, TechCrunch, VentureBeat and the Verge.
The service was made available as a web app and followed a pay-to-play model. You can watch a demo of version one below:
In this article we'll get you caught up on the new interface, our experiments using the audio-to-audio feature, comparisons to MusicGen, and some tips about how to write the best prompts.
Table of Contents
How to use Stable Audio's text-to-music generator
Stable Audio lets users generate raw audio from descriptions of music and sound in general. To get started, navigate to the Stable Audio website, sign up for free and accept their terms of service. This will bring you to the dashboard below.
A review of the Stable Audio 2.0 interface

The top left quarter of Stable Audio's interface still contains the text area where you'll enter music prompts. Below that, you'll find a new prompt library with presets laid out in a format that I've not seen offered by other services. Click on one of the cards to pre-fill the text area with key terms that the system understands. You can press play on any of these cards to audition them first.

There are 17 prompt presets in the library, with a final 18th option that says "surprise me" and will pull in one of the 17 options at random.
Below the prompt library selector is a Model selector. Choose from AudioSparx 1.0 or 2.0 if you'd like, but it probably goes without saying that the latest option is the best. The program defaults to version 2.0 by default so you can leave that as is.
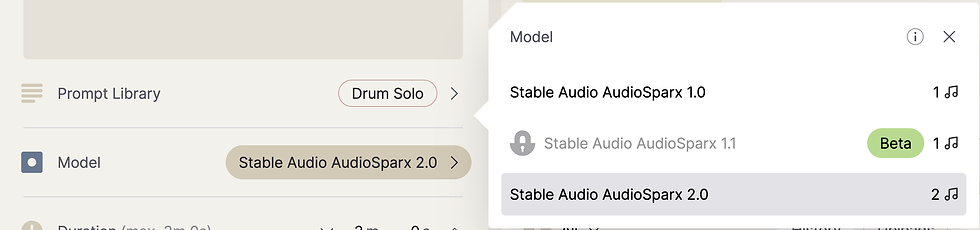
Moving down the list, you'll find controls for duration that existed in version 1.0, but things start to get really interesting in the next section, labeled Input audio. Hover over the information icon to access their full user guide. I've imported the main video from that page, so you can have a quick look below.
The user guide is quite lengthy and detailed, so if you're eager to get started you can simply hit add audio. A brief walkthrough will launch on your first go around, explaining some important details about the upload budget for each pricing tier.
Minimum file length: 1 second
Free plan: Three minutes of uploaded audio
Pro plan: Thirty minutes of uploaded audio
Studio plan: Sixty minutes of uploaded audio
Max plan: Ninety minutes of uploaded audio Stable Audio will check your files for copyrighted works and if it's found to be in violation, that audio will still be counted against the monthly allowance. So be sure to use unpublished music, even if it's your own.
Accepted file formats: MP3, WAV, MP4, AIFF.
Audio files that you upload will be automatically cropped to 3 minutes. They also clarify that your music will never be used to train any of their models.
That's all there is to it. Now you're ready to start adding audio. Choose from one of two options. You can either upload music from your computer or record it directly into the web app.

The upload option is straightforward and will simply open up your system's file browser. However, if you decide to use the record feature, you'll need to grant your browser permission to access the computer microphone as shown below:

You can monitor the number of music generation credits left in your account by referencing the music note symbol in the upper right corner. The number goes down with each track you create.
Experiment 1: Finger Snaps into Drum Beats
My first experiment involved snapping a simple rhythm for the recorded input, to see if I could get a more interesting percussive concept using Stable Audio's Drum Solo preset from the prompt library.

The results of this first "snapping" experiment were a bit underwhelming. There was a definite style / timbre transfer but it fell short of what I would call a drum solo. I tried a second prompt, drum n bass, which produced different drum sounds. Both outputs had a kind of modified snapping timbre.

Experiment 2: Hummed Melody to Synth Pop
Back to the drawing board! I recorded myself humming a simple ten second melody. Then I selected the Synth Pop preset from Stable Audio 2.0's prompt library and hit generate.
Try comparing the uploaded audio wave form below to the synth pop output. As you can see, the loudest part of the input signal corresponds to a similar waveform in the output. But if I'm being brutally honest, the style transfer did not work very well. The output sounded similar to my hum, with a slightly different timbre.


Experiment 3: Accordion Song to Gypsy Jazz
My first two experiments were a bit of a flop. Both of them involved recording into Stable Audio. So this time I tried uploading a 30 second recording of an accordion tune I wrote. It's a loud, clear recording with chords and melody. I've had success using it with MusicGen in the past, so there's a clear benchmark to compare it against.

Success, kind of! This version was without a doubt the best result so far. The prompt called for gypsy jazz with upright bass and a brushed drum set. What I got instead was an acoustic jazz guitar with what sounded like a xylophone on top. There was no bass or drums.
Some constructive criticism is warranted here. The melody was about 90% accurate, but there were a few sour notes that were not present in the original recording. It lost the thread rhythmically a few times, jumping into the melody early or too late.
On the other hand, Stable Audio did innovate on the simple i-iv-V7-i chord progression with some tasty reharmonization. If my goal was to come up with new chord arrangements, this would have been a valuable resource. I can imagine passing this into a tool like Samplab or RipX to get MIDI transcriptions and figure out precisely what chords were being played.
I continued iterating on the accordion song with new prompts, to see how it would fair. My prompt "death metal with blast beats" lacked drums or bass, but did apply a distorted guitar timbre to the original recording. The prompt "passionate tango" sounded fairly similar to the input, but a bit more pizzicato.
Takeaways on the audio-to-audio feature
As a whole, Stable Audio 2.0's audio-to-audio feature appears to be applying timbre transfer than the style transfer offered by MusicGen's melody mode. You might hear more than one instrument in the output, but in my experience, we're not getting a full multi instrumental arrangement with drums and bass yet.
I spoke with members of Stability's team, who suggested tweaking the input strength and prompt strength settings for better results. You'll find those tucked away in the "extras" section below the audio upload feature.
Additionally, the tone quality of the audio output is still a bit rough. It's low fidelity and would be difficult to imagine using in any capacity, whether for sampling in a DAW or sharing online as a creative trophy.
For instant song generation, Suno still seems to be in the lead, though Suno's quality has recently taken a hit and Twitter users have been expressing some frustration about the decline in musical innovation there as well.
How does Stable Audio compare to MusicGen?
Stable Audio and Meta's MusicGen are both AI text-to-music platforms, but as I've just explained, MusicGen includes a melody mode that creates full instrumental arrangements. Users can upload audio files to MusicGen and submit text prompts to modify them. Have a look at the demo below for an example:
We've previously covered several use cases for MusicGen, including the creation of film scores and infinite music. You can watch a demo of MusicGen's audio conditioning below:
The MusicGen model doesn't have a dedicated user interface, though third party websites like SoundGen have created custom UIs. So perhaps one of the key differences with Stable Audio is that the model and the web interface are built by the same company.
Stable Audio 2.0 has a particularly beautiful interface, which deserves some praise. All in all, I think it's fair to call Stable Audio the more consumer-friendly service.
Using AudioSparx to guide Stable Audio prompts
This brings us back to the core Stable Audio product. Exciting as audio-to-audio may have been, their bread and butter is still pure text-to-music. If you're okay with returning to that core experience, AudioSparx 2.0 output does sound better than the first model.
So then, the million dollar question is: What the hell do I type into this thing?
Stable Audio's AI model was trained on AudioSparx, a dataset with over 800,000 audio files and 19.5K hours of music, sound effects, and single-instrument stems.
Having trained exclusively on audio from this library, the model performs best when you use terms that align with that dataset. To discover the terms in their training data, navigate to the AudioSparx website and click on the music tab.
The following dropdown menu will appear:
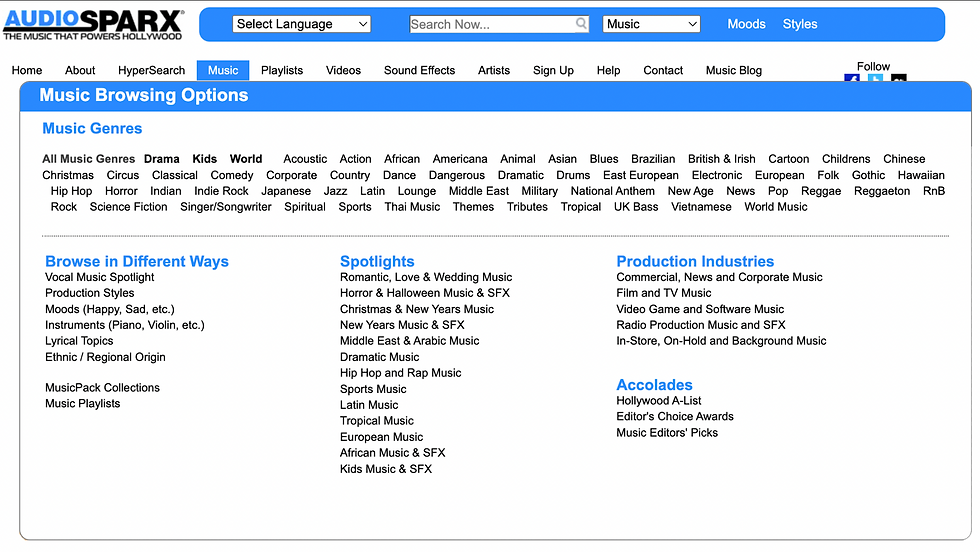
Each of the top-level music genres are linked to a separate page, where visitors will find a list of relevant subgenres.
In the example below, we've selected electronic music and are viewing the first few subgenres, listed alphabetically. The number of tracks in each collection is indicated to the lefthand side of the label. Subgenres with a greater number of tracks may lead to a richer and more diverse set of ideas for Stable Audio to draw from when it's time to generate music.

Click through a subgenre to view the full collection of audio files it contains. Under the title of each track, you'll find a rich text description. Try copying and pasting the descriptive text directly into Sample Audio's prompt field and see what happens. Tweak the text and iterate through multiple rounds until you're satisfied with the music it creates.

Just be careful when using descriptions that contain the name of artists. The third example, shown above, names Aphex Twin, Radiohead, and others.
As we explain later in this article, Stable Audio's terms of service forbids the misuse of intellectual property. I didn't see any lines specifically stating that users cannot submit artist names in their prompts, but read between the lines and this is the most obvious interpretation.
My interpretation is that you are probably safe to experiment with artist names as long as it's for your own enjoyment. For ethical and legal reasons, it would be best to avoid using music commercially that was seeded from artist names.
The Genre Fusion technique by CJ Carr of Dadabots
CJ Carr of Dadabots has been a part of the Harmonai team for several years. He's one of my personal favorites in the AI music space, because of his anachronistic and mind-bending approach to audio synthesis.
The video above begins with a quick overview from CJ, explaining how the system works, followed by a demo of his new genre fusion technique. What happens when you mash together two unlikely genres? Can we create entirely new styles of music, the likes of which the world would otherwise never have heard?

Genre Fusion prompt format: The prompt format in this demo combines two phrases, each prefixed with "Subgenre: " and separated by a pipe symbol (|).
Ideas for experimenting: Try entering two styles that are known to have opposite tempos, like "Subgenre: Breakbeat|Subgenre: Lo-fi Hip Hop". You can also try genres with opposite styles like "Subgenre: Death Metal|Subgenre: New Age Relaxation".
At any other time in history, genre fusions like this would have been stuck in a kind of unexpressed, latent space. But now, with a few bits of text and a moment of processing, Stable Audio do the heavy lifting for us and present us with new ideas.
Genre bending is a safer alternative to what I would call artist blending. The prompt can swap in the word artist for subgenre and create hybrids of multiple artists. But as I mentioned earlier, we're entering a legal gray area as soon as we start injecting individual artists' brands into our prompts.
So on that note, let's have a closer look at the terms of service.
Stable Audio's Terms of Service

Most of us skip right through the terms and service agreements when we register for a new app. But when it comes to AI music generation, it's important to have a basic familiarity with their terms.
Here are some of the most important things to know about Stable Audio's TOS:
Age limit: You've got to be 13 years of age to legally use the service
The music is yours: Users own the content they generate, subject to the terms and laws.
Don't train other AI models with Stable Audio: Users are prohibited from using the services or its generated content to train other AI models.
Respect artist IP: Users must not infringe on intellectual property.
No class action lawsuits, please: Both parties waive the right to a jury trial. Disputes between you and "Stability" will be settled through binding arbitration rather than in court. Small claims court can be used for individual claims, and you can report to federal or state agencies.
Dispute Resolution: Both parties must try to resolve disputes informally for 60 days after notice is given. If unresolved, arbitration can commence.
Confidentiality: Arbitration proceedings are confidential.
Opt Out: You can opt-out of the arbitration agreement within 30 days of account creation by notifying Stability.
If you get sued, you pay the legal bills: Users indemnify Stability against claims arising from intellectual property infringement, misuse of the Services, or violation of the Terms. Stability and its representatives are not liable for indirect, special, or consequential damages or losses.
Summary of pricing for free, premium and enterprise tiers
Free Tier users are capped at 20 tracks per month with a maximum of 45 second duration. They cannot use generated content commercially.
Professional Tier users get 500 tracks per month with 90 second duration and can use the music for commercial projects of less than 100K monthly annual users.
Enterprise Tier users can customize the max duration and volume of music generation, but need to contact the company for a quote. See details on the pricing page.
This is only a summary of terms and should not be considered a complete report. We've covered the points that we found to be the most relevant, but you should still read the TOS before signing up.
Backstory: Harmony, Dance Diffusion and Riffusion
After struggling to raise funding at a higher valuation in June 2023, Stability seems to have felt some pressure to build a profitable service. September's flood of user traffic will likely improve investor sentiment, especially if they can become profitable and deliver reliable service.
Stability's first popular AI music models, like Disco Diffusion and Dance Diffusion, were developed by the company's audio lab Harmonai. They were adopted at the grassroots level, by people running the models in Google Colab and on Hugging Face. These interfaces were a bit technical for the average user.
The decision to launch a text-to-music service may have been inspired in part by Riffusion. Published by third party developers in December 2022, the web app leveraged Stability's image generation to train on labeled spectrograms (images of sound) and generate new spectrogram images from text. Riffusion then stitched these clips together and sonified them, meaning they turned the image data into sound.
In October 2023, Riffusion received a $4M seed round of funding and pushed out a new interface with singing voices and music generation, comparable to Suno.
Stable Audio 2.0 is a step forward, but it's an open question as to whether they'll be able to compete with the mass appeal of singing voices. The quality of the audio-to-audio feature also needs some improvement. It's their biggest differentiator, so if they can improve on that, it might put them back in the running for musicians, if not the general public.